

TL;DR;
· Graph databases are ideal for query use cases with data with complex relationships and layers of connections
· Its query language is fast, efficient and allows for retrieval of information at deeper levels of abstraction in the data
· Neo4j is currently the most popular Graph database, and its declarative query language is Cypher
· Concepts in Cypher are “nodes”, “relationships”, and “properties” for storing the data
· Keep queries small and simple for best performance
During the past decade, data have piled up increasingly and became more diverse in nature: a development that is asking more and more from the databases they are stored in, creating all sorts of challenges ranging from organizational, to scaling, to security. Therefore, a movement toward different databases and different store technologies for different use cases has arisen.
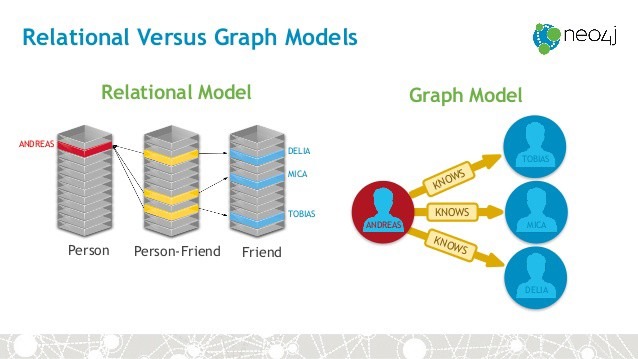
In traditional senses, all data would be stored inside one database that essentially is a relational database. When new relationships would be encountered, exhaustive joins would be executed with SQL in order to add these relationships. Moreover, when examining these relationships at diverse levels, querying becomes slow and inefficient. In case we’d stumble upon ready-to-read and read-only purpose data, we’d have to ask ourselves if this really is best practice or if we’d have to look further for other, non-relational, database types to store these specific types of data.
For visualizing and studying complex relationships, Graph databases are more than convenient. They can be used to do easy, simple and fast querying, or even search via a user-friendly UI such as in the graphical exploration application Neo4j Bloom. The queries are smaller, more elegant, faster and consistent in performance when retrieving relationships. Graph databases are also very good at diving into the deeper layers, and they display flexibility over time and use. The returned graphs visually display relationships between elements, that provide insights of added value in the data.
So, what are Graph databases?
Graph databases use graph structures for semantic queries. The graphs consist of nodes, edges and properties to represent and store data, and therefore look like network models. These are in contrast to, but also closely related to, relational databases. Relational databases are more of the type “rows in tables”, where the relationships are (foreign key) constraints. In Graph databases, relationships are stored as a first-class entity and they are aimed at storing data with many layers of connections, adding richness of depth to the data. Therefore, they allow for an advanced level of abstraction by going deeper and deeper into the layers of data. Graph databases generate the graphs by computing the shortest path between two (or more) nodes. They also do well in searching and visualizing patterns. The most popular, mature and deployed Graph database is Neo4j which ranks high among all used databases, however, relational databases are still at the top of the list. Other Graph databases include OrientDB, AllegroGraph, AnzoGraph and Oracle’s Spatial and Graph option.

When to use a Graph database?
It all comes down to choosing the right tool for the job, meaning the choice for a Graph database depends on the type and structure of data to be incorporated and the future wishes for the data and schemas. Using a graph-oriented database would definitely make sense if:
… the data have many layers of connections.
… relationships frequently are many-to-many.
… the relationships are equally relevant or even more important than the entities themselves.
… the possibility exists that the database will gain in complexity.
… low latency for return of information is a recommended feature.
… the queries are small and simple.
A selection of use cases:
![]() Fraud detection
Fraud detection
![]() Real-time recommendation engines
Real-time recommendation engines
![]() Graph-based search (think of Bixby/Pinterest)
Graph-based search (think of Bixby/Pinterest)
![]() Customer 360
Customer 360
![]() Social networks
Social networks
![]() Network and IT-operations (IoT)
Network and IT-operations (IoT)
![]() Master data management (MDM)
Master data management (MDM)
![]() Identity and Access management (IAM, like f.e. LDAP)
Identity and Access management (IAM, like f.e. LDAP)
![]() Asset Management
Asset Management
![]() Knowledge graphs (for example what does your company know and who owns this knowledge?)
Knowledge graphs (for example what does your company know and who owns this knowledge?)
Neo4j’s query language: Cypher
Cypher is a declarative query language for Neo4j. Neo4j is implemented in Java but accessible from software written in other languages by using Cypher, for example, through the built-in REST API. Neo4j’s query language Cypher allows for fuzzy queries. And, according to its developers, it upholds the ACID standards (Atomicity, Consistency, Isolation, and Durability) to ensure the data is safe and stored consistently.
Some concepts and rules
In Graph databases different concepts apply to the data than from a relational database point of view. For Graph databases in Neo4j:
![]() a “node” is an object or entity, such as a person or an artefact. It can be labelled.
a “node” is an object or entity, such as a person or an artefact. It can be labelled.
Example – ‘:Person’, ‘:Vehicle’, ‘:Car’
![]() a “relationship” is the edge between the nodes, a label to describe a relationship with a direction & diverse connection types. It can have properties.
a “relationship” is the edge between the nodes, a label to describe a relationship with a direction & diverse connection types. It can have properties.
Example – ‘LOVES’, ‘LIVES WITH’, ‘DRIVES’, ‘OWNS’
![]() “properties” are additional information either applying to the node or the relationship.
“properties” are additional information either applying to the node or the relationship.
Example – ‘since:’
![]() a “traversal” navigates through a graph and finds paths by means of queries (Cypher).
a “traversal” navigates through a graph and finds paths by means of queries (Cypher).
![]() “paths” are retrieved from traversal.
“paths” are retrieved from traversal.
![]() “schemas” are optional and can be added to increase performance or gain modelling benefits. It can also be added after some time if it is desirable.
“schemas” are optional and can be added to increase performance or gain modelling benefits. It can also be added after some time if it is desirable.
![]() “indexes” on properties are helpful to improve speed of lookup and gain performance.
“indexes” on properties are helpful to improve speed of lookup and gain performance.
![]() a “constraint” is useful in keeping the data clean, allowing specification of a set of rules for what the data should look like.
a “constraint” is useful in keeping the data clean, allowing specification of a set of rules for what the data should look like.
When the graph model is defined (nodes, relationships and properties), the data can be loaded into the database. Subsequently, the database can be queried. The Cypher Query Optimizer decides how to traverse the graph based on the queries applied on the database. NOTE: If speed matters, it is possible to write Native Server-Side Extensions for Neo4J in Java when building the model in order to hardcode the route for traversing the graph with queries. This would allow for some milliseconds increase in response times. Important query-rules are:
Nodes are surrounded by parentheses ‘()’ and tags end with ‘:’
(p1:Person)Properties are surrounded by curly brackets ‘{}’
(p1:Person {name: ‘Sasha’} )Relationships are wrapped by hyphens ‘[]’ and direction is indicated with ‘<’ and ‘>’ or omitting the direction by ‘-’
(p1:Person {name: ‘Sasha’} ) - [l:LOVES] -&gt;Properties on relationships
... - [l:LOVES {since: ‘summer of 1969’} ] -&gt;Cypher is case-sensitive for nodes or node labels, relationship types and property keys, since these are manually assigned. Cypher is case-insensitive for cypher keywords such as MATCH and RETURN, which are also understood if written “MaTcH” and “rEtUrN”. However, consistency in the query code is good practice.
To ensure uniqueness when naming nodes by using labels (e.g. ‘p:’), apply constraints at every start:
CREATE CONSTRAINT ON (p:Person) ASSERT p.name IS UNIQUELet’s say there are two Sashas, then constrained validation failed! So, you have a check in there 🙂 For more understanding of the Cypher queries, try for yourself with the Neo4j Demo below.
It is possible to convert relational database data to graphs by locating the foreign keys, join tables, and replacing them by relationships with or without properties.
A Neo4j Demo
Setting up a Neo4j database
Run any VM with Docker Host. Official Docker images are available for Neo4j. Here we use Neo4j 3.0.
Create the directories “neo4j/data” and “neo4j/logs” inside your home directory.mkdir ~/neo4j/logs mkdir ~/neo4j/dataThen simultaneously download and run the docker image:
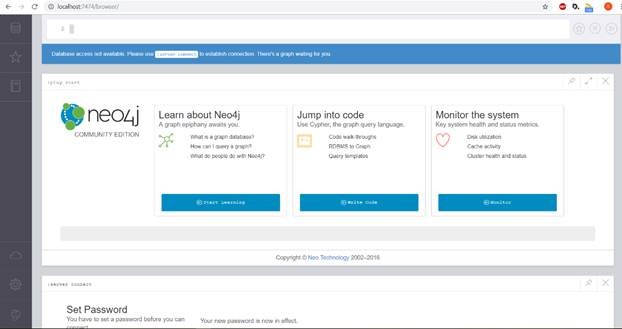
docker run --publish=7474:7474 --publish=7687:7687 --volume=$HOME/neo4j/data:/data --volume=$HOME/neo4j/logs:/logs neo4j:3.0Open your browser on port 7474, such as http://localhost:7474. You’ll be asked to connect to the database. Use: neo4j/neo4j. Then create your own password, which will allow you to access your own database at any time. This is what the Neo4j UI looks like in the browser:
To fill the database, see the .txt document added here.
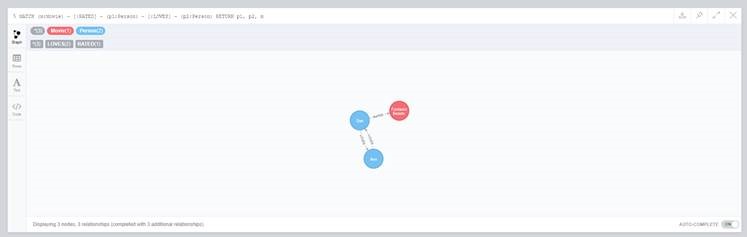
To show the complete graph:
MATCH (n) RETURN n
Querying the graph database
When retrieving persons that have rated movies, we’re using the MATCH-statement in order to specify which entities and relationships we want to return from. Since we want all people, with any rating for any movie, we’re only matching for the node-labels:
MATCH (p:Person) - [:RATED] -&gt; (m:Movie) RETURN p, m
When returning movies that were rated with a 6 and the people who rated it, we’re specifying the property:
MATCH (m:Movie) - [:RATED{rating: 6}] - (p1:Person) RETURN p1, m
Return a movies rated by two people that rated the same movie by a 9:
MATCH (p1:Person) - [r1:RATED {rating: 9}] - (m:Movie) - [r2:RATED {rating: 9}] - (p2:Person) RETURN p1, p2, m
MATCH (p1:Person) - [r1:RATED] - (m:Movie) WHERE r1.rating &lt;5 RETURN p1,r1
Retrieve a movie that has been rated by a person who loves another person:
MATCH (m:Movie) - [:RATED] - (p1:Person) - [:LOVES] - (p2:Person) RETURN p1, p2, m
MATCH (dan:Person {name:"Dan"})-[r:LOVES]-&gt;(ann:Person {name:"Ann"}) WHERE ID(r)=21 CREATE (ann)-[r2:LOVES]-&gt;(dan) SET r2 = r WITH r DELETE rYou can also remove a node by using its ID, or without it you can use its property (when unique):
MATCH (p:User) where ID(p)=1 OPTIONAL MATCH (p)-[r]-() //drops p's relations DELETE r,pDelete a relationship with an empty node (make sure to specify correctly):
MATCH (n) WHERE NOT (EXISTS (n.name)) DETACH DELETE nIf you want to start for yourself
In conclusion, Neo4j is a great Graph database that is easy to use and understand. Letting go of the relational databases is definitely not necessary, since the Graph databases can be useful as an addition to them, especially for (parts of your) data that are strongly interconnected. They leverage the relationships, optionally can provide some level of decoupling from the original data source, and allow fast and simple data retrieval at various depths that bring added insights in the data and their relationships.
Some additional links:
WTF is a Graph database? – Ed Finkler 2016, hilarious video
Query the graph database with a Spring Boot REST-API
Neo4j tutorial series #5 and #6
Neo4j stepping in to combat fake news







{kind=link}
{kind=link}
{kind=link}
I can’t load the file fillNeo4jDatabase.txt
Dear Adrew,
If I’m correct, you’d be able to open the link now. If you still have troubles opening it, please let me know.
Cheers,
Rosanna