

{kind=link}
This article highlights a use case implementation I recently implemented (for a demo session) leveraging Oracle Functions as well as OKE (Oracle Kubernetes Engine), Object Storage and Elastic Search. I will briefly touch upon some of the interesting aspects of implementing this case. The code for the function and its deployment can be found in this GitHub repo: https://github.com/lucasjellema/soaring-logisticsms-shippings-reporter-func .
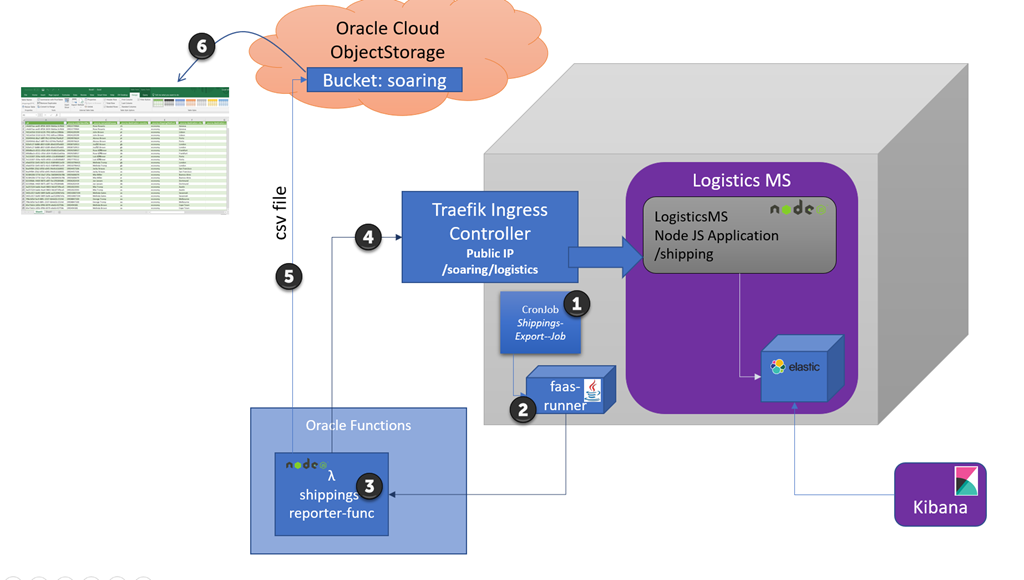
The next figure illustrates the story of this article: a CSV file is produced every 25 minutes on Object Storage with the Shipping records retrieved from the Elastic Search index inside the Logistics MS. This is done by an Oracle Function.
 1. A CronJob on Kubernetes runs every 25 minutes.
1. A CronJob on Kubernetes runs every 25 minutes.
2. It runs a container that contains the OCI Functions Java SDK and a small Java application to invoke the Function. The input to the function is passed from the CronJob to this Java application and from there to the Function (note: Oracle Functions will shortly supported scheduled execution of Functions; at that time, steps 1 and 2 in this picture are replaced with a single scheduling definition
3. The Function runs in the managed Oracle Functions FaaS environment, a serverless execution for which I only provided the (Node) code.
4. The shippings-reporter-func function invokes the Logistics microservice to retrieve today’s shipping details. This call is received on the IngressController on the Kubernetes cluster
5. The JSON based data returned from the Logistics Microservice is processed into CSV (using npm module json2csv); next, the OCI REST API for the Object Storage service is invoked to create the csv file in the soaring bucket
6. Download the csv file from the web console and open it in Excel to start exploring the data. Actually, my target is Oracle Analytics Cloud, the next step on this trip
The Excel file opened from the CSV file:

Inspect and download the CSV file from Object Storage

The CronJob on Kubernetes:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: shippings-reporter-job
namespace: soaring-clouds
spec:
# once every 25 minutes - see https://crontab.guru/
schedule: "*/25 * * * *"
jobTemplate:
spec:
template:
spec:
hostAliases:
- ip: "169.46.82.169"
hostnames:
- "logs2.papertrailapp.com"
containers:
- name: shippings-reporter-job
image: lucasjellema/function-invoker:1.0
args:
- /bin/sh
- -c
- /tmp/invokeFunction.sh '{"period":"day", "additional information":"none"}'
env:
- name: "FUNCTIONS_COMPARTMENT"
value: "amis-functions-compartment"
- name: "FUNCTIONS_APPLICATION"
value: "soaring"
- name: "FUNCTION"
value: "shippings-reporter-func"
restartPolicy: OnFailure

The function output on Papertrail:

The Shipping records are collected in Elastic Search and can be inspected in Kibana:

and the individual records:

Details on how to invoke the Object Storage API from Node on Oracle Cloud Infrastructure are in this article: https://technology.amis.nl/2019/03/16/save-file-to-oracle-cloud-infrastructure-object-storage-from-node-through-rest-api/
It might be interesting for when you ever may have to transform JSON data (or just JavaScript data structures) to CSV file to take a look at saveObject.js and the use of the json2csv module.
const Json2csvParser = require('json2csv').Parser;
const rp = require("request-promise-native");
async function getShippingsData(period) {
var options = {
method: 'GET',
uri: `http://host/soaring/logistics/shipping/period/${period}`,
json: true // Automatically parses the JSON string in the response};
}
try {
let response = await rp(options);
return response
} catch (error) {
console.log("Error: ", error);
}
}//getShippingsData
async function runShippingExtractionJob(objectName, input) {
var period = input.period || 'day'
logger.log('info', `runShippingExtractionJob for ${JSON.stringify(input)} for period ${period}`)
var shippings = await getShippingsData(period)
// see https://www.npmjs.com/package/json2csv
const fields = ['_id', '_source.orderIdentifier', '_source.nameAddressee', '_source.destination.country'
, '_source.shippingMethod', '_source.destination.city', '_source.destination.coordinates.lat', '_source.destination.coordinates.lon'
, '_source.shippingStatus', '_source.shippingCosts', '_source.submissionDate'
, '_source.items.productIdentifier', '_source.items.itemCount'];
const json2csvParser = new Json2csvParser({ fields, unwind: '_source.items' });
const csv = json2csvParser.parse(shippings);
logger.log('info', `Parsing to CSV is complete, size of CSV document: ${csv.length}`)
...
Note to myself: my Excel environment is default set to The Netherlands, which means that the interpretation of the decimal and thousands separator is reversed from what the US does. I have to take these steps in Excel before reading the CSV file:





Resources
Node module json2sv – https://www.npmjs.com/package/json2csv